
Growth Engineering in the Age of Agents
How ambitious AI startups become the default in their category.

The default in your category is being rewritten inside the code agents ship.
When Claude Code was asked to add email to an app, it picked Resend 62.7% of the time and SendGrid 6.9% (even though SendGrid has been deeply embedded in enterprise email for decades and was acquired by Twilio for $3 billion). The same pattern shows up in databases. For a client-side React app, Claude Code picked Supabase as the database 70% of the time over. MongoDB, one of the database names most developers recognize, received zero primary picks in the broader database category even though it appeared often enough to show the model knew it existed. Being known by developers is not the same as being chosen by agents. Agents pick what they can turn into working software.
Interestingly, in 12 of 20 software categories, Claude Code often built the feature itself rather than use a popular tool.
That is the opening for ambitious AI startups.
In a world where Claude Code and its peers make it cheap for more people to produce a competent first version of almost anything, building stops being the only scarce resource. Distribution becomes the advantage, not distribution as a big splashy launch post or a bigger ad budget, but distribution inside the build path: becoming the product the agent reaches for and the workflow it can complete without a human stepping in.
Growth engineering becomes a crucial discipline because the selection surface has moved into the build path.
Growth engineering in the age of agents is the discipline of making machines discover your product, select it, use it successfully, and bake it into their workflows. The goal is to become the default in your category: the product agents reach for when they are trying to get a job done.
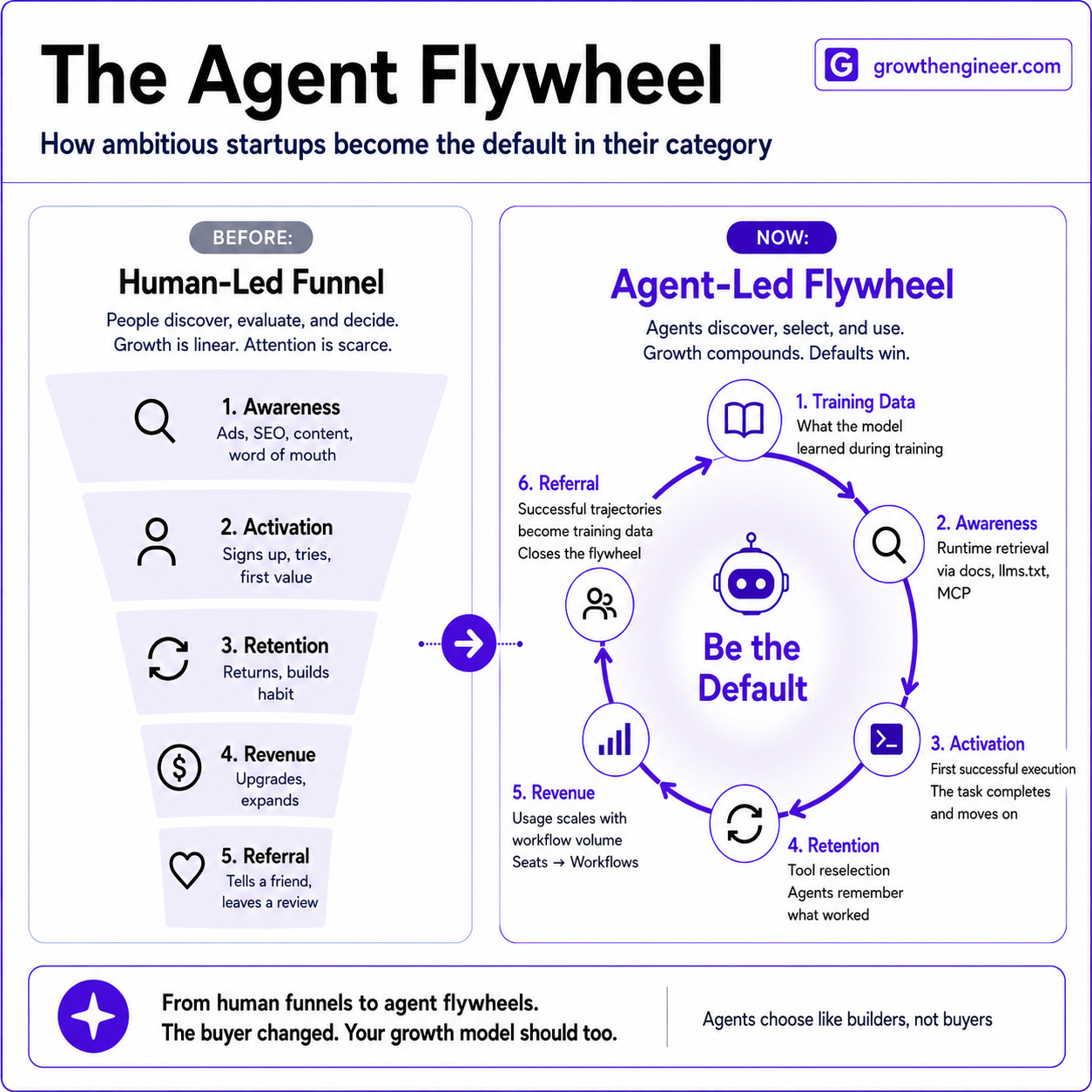
The old software market was shaped by human evaluation: a buyer discovered the incumbent through word of mouth, read reviews, opened pricing pages, took demos, asked a friend, and chose. The agent market works differently because the evaluation happens when the agent is building. Your homepage can be persuasive and still irrelevant to the decision if the agent cannot use the product from the repo: discover it in context, authenticate without a human-only gate, make the first call without being blocked by needing to enter a credit card, recover from the first error, and verify that the result worked.
For humans, the UI was the product surface. For agents, the API is the UI. A beautiful dashboard does not matter if the path breaks on a credit-card gate, a human-only login flow, an email confirmation link, unclear docs, missing test credentials, or an error message with no next step.
The product is not agent-ready until the agent can complete the loop.
That loop is simple: find the product, get access, make the first call, handle the first error, verify the result, and decide to use it again.
It’s not that Resend, Supabase, or a custom feature-flag system are always the best choices. It’s that a product the agent can execute easily is better, in that moment, than a more established product it cannot use end to end. In practice, agents will choose something slightly worse if it’s easier to implement.
The product humans love is not always the product agents pick as the default.
That is why growth has to move closer to the product surface. In the human funnel, you could lose a buyer on the landing page and still see the visit. In the agent funnel, you can lose the decision before your site loads, before a user signs up, and before your analytics records anything. You do not get a cancellation email when an agent routes around you. You get ghosted by the machines.
I learned the precursor to this at Weights & Biases. When I joined as one of the first 10 employees, the product had about 100 users. Over the next seven years, I led growth to make W&B part of the daily workflow for millions of AI engineers. Our growth was built around human powered flywheels. A developer at OpenAI added a line to a training script, then a teammate copied it, a blog post included it, and a repo fork inherited the code. The product moved through code before it moved through a funnel.
In the human-led era, that was developer adoption. In the agent era, the same flywheel runs faster: agents copy patterns, instantiate defaults, write config, and turn one successful integration into training data and thus the next model’s default. The companies that understand this early will compound because every successful agent execution can become public signal, copied code, better retrieval, and stronger memory in the next model cycle. The companies that treat it as a marketing channel may look fine until the default has already moved.
Agents compress the work SaaS used to sell
SaaS became valuable by packaging work for humans: interfaces to navigate, workflows to follow, dashboards to monitor, and seats to provision. Agents threaten a specific part of that value, not the software business itself. When an agent can use files, apps, connectors, and role-specific skills to return a finished deliverable, it can skip parts of the interface layer that SaaS used to monetize.
SaaS was priced for seats. Agents buy outcomes.
In the SaaSpocalypse, investors weren’t necessarily predicting that every SaaS company would die. They were repricing companies whose value depended on humans sitting in interfaces to get work done. Reuters reported that the S&P 500 software and services index had shed about $1 trillion in market value since January 28, 2026. The same report noted that Thomson Reuters suffered a record one-day plunge after investors worried an Anthropic plugin could compress legal workflows, with ServiceNow, Salesforce, and Microsoft also hit.
It wasn’t as much that one Claude plugin erased a trillion dollars, but that the market was asking a new question: what is left when agents can compress the work your product used to package?
Durable software will still have proprietary data, trust, governance, deep integrations, reliability, workflow ownership, and human budget approval. But products whose value is mostly interface, coordination, and seat packaging now have to prove why an agent cannot route around them. A human used to choose a tool, then tell the software what to do. Increasingly, the human states the outcome, and the agent chooses the tools, or decides it does not need one.
Agents choose like builders, not buyers
The opening examples are not edge cases. They are the new pattern. Amplifying.ai pointed Claude Code at real repositories 2,430 times, with no specific tool names in the prompts, and watched what it used when it had to ship code.
The data shows that when a tool made the job easy, Claude Code collapsed the category into a default tool, ignoring the rest. When the job looked small enough, it skipped the vendor entirely. Custom or DIY was the top label in twelve of twenty categories. Feature flags became a config file. Python auth became JWT and bcrypt. Rate limiting, caching, background jobs, and other “products” often became code.
That is the lesson: agents do not care whether your category exists. They care whether the job can be completed. A product that sells a workflow but does not own a durable primitive underneath it is now competing with the agent’s ability to write the workflow away.
The default tool choices also move faster than revenue. Across Claude model generations, Prisma fell from 79% to 40% to 0% of JavaScript ORM picks while Drizzle moved from 21% to 60% to 100%. The customers did not all churn together. The default inside the code moved first.
This is the default decay: the loss of agent-selection position across model releases, often before the revenue dashboard notices.
A product can lose distribution before it loses revenue.
There is not one agent market either. Claude Code and Codex agree on some defaults and diverge sharply on others, which means a founder cannot optimize for a single model anecdote. The new question is not just where developers hang out. It is which agents matter for your category, what they already believe, and what signals will change their future defaults.
Growth engineering is no longer funnel optimization
Growth engineering used to mean building the machinery around a visible human funnel: landing pages, instrumentation, onboarding, referrals, experiments, lifecycle loops, and the infrastructure that made acquisition measurable. That work still matters, but it no longer reaches the first decision in an agent-mediated adoption path.
The agent does not enter through your homepage. It enters through the corpus, the repo, the docs, the package manager, the registry, the API, the error message, and the payment rail. Growth work therefore moves into surfaces that product and engineering teams own.
The worst state is not being unknown to buyers. It is being agent invisible: absent from the build path, unable to be found, authenticated, called, or verified by a machine.
This is the difference between supply-side and demand-side agent-led growth. AI SDRs automate your selling motion. Demand-side agents work for the buyer. They search, evaluate, implement, test, and sometimes transact before a sales conversation ever happens.
The first experience of your product may now be a line of code written by an agent that has never seen your homepage.
That makes growth engineering a technical discipline. The questions are no longer only whether a human can find you, understand you, sign up, and activate. The questions are whether an agent can discover you, authenticate, make the first call, recover from failure, verify success, and choose you again.
Parametric lock-in is the new moat
Agents do not start every product selection decision from zero. They inherit defaults from their training data, which includes code, docs, tutorials, repos, package examples, and previous completions. When an agent reaches for a library, API, or workflow, it is often reaching for the pattern that already feels most available.
That is parametric lock-in: competitive advantage encoded in model weights.
It is not a brand moat or a network effect in the old sense. It is a statistical default inside a model that has already shipped. You cannot charm it with discounts and cold-emails, or ask it for a clean explanation of why it prefers you. You can only shape the surfaces that teach the next model what to remember.
The flywheel is simple. Agents pick your product. They write code that uses it. Developers ship, fork, copy, publish, and document that code. Those examples become part of the public corpus and retrieval layer. The next model sees more of you in the right context, so the next agent is more likely to pick you again.
The reverse loop is just as important. If agents stop picking you, fewer new projects use you, fewer examples enter the corpus, and your future distribution gets thinner. By the time revenue shows the damage, the default may have moved one or two model generations ago.
Parametric lock-in is powerful, but it is not magic. It is strongest when agents rely on memory, weaker when they retrieve current docs, weaker still when they can test tools at runtime, and weakest when performance is easy to measure.
That is the startup opening: incumbents can own historical memory, but startups can still win the runtime test.
The durable company needs both. It has to be present enough to enter the model’s consideration set in the training data and executable enough to survive the first run. Memory gets you considered. Execution gets you chosen.
Distribution now has three machine surfaces
The old growth optimizations centered around time-to-value: how fast can a human get to the aha moment?
The agent-era optimization centers around token-to-value: how many tokens, steps, tool calls, credentials, retries, and context hops does it take before an agent can produce a verified result with your product?
Lower token-to-value becomes a distribution advantage. If two products solve the same problem, the agent will tend to favor the one it can remember, discover, call, and verify with less context and fewer failure points.
That advantage is built across three machine surfaces.
The first surface is memory: what the model already knows. Public code, package usage, docs, tutorials, GitHub issues, Stack Overflow answers, benchmarks, and examples teach future models what a normal solution looks like. Memory is slow to earn, slow to lose, and slow to repair. It gets you into the agent’s consideration set.
The second surface is runtime discovery: what the agent can find in the moment. This includes docs, package metadata, examples, registries, llms.txt, MCP servers, tool descriptions, and API references. Runtime discovery matters because not every product can be known at training time. A startup with weak memory can still win if the agent can find the right interface and use it cleanly.
The third surface is the harness: the environment where the agent acts. Claude Code, Cursor, GitHub Copilot, ChatGPT, Loveable, enterprise agent platforms, internal developer portals, and workflow orchestrators are not neutral windows. They have defaults, connectors, allowlists, registries, telemetry, permissions, and UI affordances that shape what the agent can see and execute. Harness placement may become the agent-era version of getting into the app store.
Token-to-value optimization is important across all three. A product can be known in memory and still lose if the docs burn too much context. It can be discoverable at runtime and still lose if authentication requires a human. It can be present in the harness and still lose if the first error cannot be recovered from.
The new growth stack is:
Be remembered in the corpus.
Be discoverable at runtime.
Be available in the harness.
Be callable through a small, legible interface.
Reduce token-to-value.
Make first execution work.
Make errors recoverable.
Make pricing and payment workflow agent-friendly.
Be worth reselecting.
That is the machine distribution system: memory gets you considered, runtime discovery gets you found, harness placement gets you into the path, and token-to-value decides whether the agent keeps going.
Lower token-to-value is a huge distribution advantage.
Your growth dashboard cannot see the first adoption event
The old funnel dashboard starts too late for today’s world. It sees visits, signups, sessions, seats, and revenue. In agent-led adoption, the decisive event can happen before any of those exist: inside an IDE, terminal, repo, browser agent, orchestration layer, or workflow your product analytics never sees.
DAU and MAU were useful when a login was a reasonable proxy for value. With agents, login is not enough, and usage is not always value. The unit that matters is the completed workflow.
The north star becomes Weekly Active Workflows: how many valuable workflows were completed successfully in the last week, whether initiated by a human, an agent, or both.
The supporting funnel metrics change too. The top of the funnel has to be measured outside your product.
Awareness becomes AI Citation Share: when models are asked what to use in your category, how often do they name you, in what rank, and with what caveats? Presence becomes Public-Code Footprint: how often your product appears in public repos, examples, imports, templates, and recent projects likely to feed the next training or retrieval cycle.
Activation becomes First Successful Execution: the first time an agent completes the intended job with your product in the loop.
Time-to-value becomes token-to-value: how many tokens, calls, retries, docs pages, credentials, error messages, and human interventions it takes before an agent gets the first correct result.
Retention becomes Agent Retention: when the same agent, user, project, or organization has the same job again, does it choose you again?
The most useful diagnostic is the gap between the two awareness numbers. If public-code footprint is high and citation share is low, the models have seen you but do not choose you. If citation share is high and public-code footprint is low, you may be living off old memory the next model will not inherit. If both are high, you are compounding. If both are low, you are agent invisible.
Your analytics tell you what happened after adoption. Agent-selection metrics tell you whether adoption is likely to happen at all.
Agent experience is distribution
Agent Experience, or AX, is the product surface agents see: it encompasses whether they can discover you, understand when to use you, call you correctly, recover from errors, and verify that the job worked. For growth engineering, that surface is not just usability, it is distribution.
Growth engineering adds the sharper point: AX is not only usability. It is distribution.
Agents choose what they can execute. That turns small product details into growth surfaces. Clean APIs influence selection. Precise tool descriptions improve routing. Stable schemas support agent retention. Useful errors enable recovery. Working starter templates become public examples, copied by other humans and agents, and eventually training data for the next models.
Selection debt is the accumulated friction that makes an agent less likely to choose you: messy docs, unclear APIs, brittle auth, bloated tool surfaces, ambiguous names, bad errors, missing examples, high token-to-value, and pricing paths that require human rescue.
This is why a docs fix can now be an important growth experiment. One study of MCP tools found that almost every tool description had at least one quality issue, and that improving descriptions increased task success and partial goal completion. The learning is not that every product needs a huge MCP server. It is usually the opposite. Agents degrade when they face too many overlapping tools, bloated schemas, unclear names, or ambiguous operations.
A product with three excellent operations can beat a product with forty endpoints exposed indiscriminately, because agents reward the shortest reliable path from intent to result.
That is token-to-value: the amount of context, code, setup, correction, and retry an agent spends before your product produces a verified outcome.
First execution is no longer onboarding polish, it is critical to long term distribution.
A human who fails once might search the docs, ask support, or come back later. An agent that fails may route around you, and the code it writes without you may become the public example the next model learns from.
You can become the default, or become the primitive
Going back to the Amplify study that showed Claude Code often built the feature itself in 12 of 20 software categories, rather than use a popular tool. If agents often build instead of buy, the first conclusion could be that many software categories are doomed. The more we think about it, I think founders have two ways to win.
The first is to become the default. In this strategy, agents pick you directly when they need the job done: email, payments, deployment, observability, search, databases, authentication, evaluation, or whatever category you own. This requires memory, runtime discoverability, strong examples, low token-to-value, clean pricing, and enough public proof that the agent trusts the path.
The goal is not to appear in the list. The goal is to become the default.
The second is to become the primitive. If the agent is going to build the visible feature itself, make your product the substrate it builds on: the identity layer under auth, the event pipe under analytics, the index under search, the sandbox under agents, the scheduler under workflows, the evaluator under model quality, or the payment rail under transactions.
In the old SaaS world, losing the branded app usually meant losing the customer. In the agent era, the branded app may matter less than the primitive that keeps appearing inside generated workflows.
That is the opening for startups. A startup does not need to outbrand the incumbent in the human market if it can be simpler for the agent, easier to call, more reliable on first execution, better represented in public examples, or more useful as the primitive underneath the workflows agents already build.
If agents write the app, own the thing the generated code cannot avoid.
Humans still buy, but agents increasingly decide what ships
The strongest objection to this strategy is true: humans are still here.
Humans decide what matters. They set strategy, approve budgets, manage risk, judge taste, build trust, handle politics, and define quality. The point is not that humans disappear. The point is that the path from intent to implementation increasingly passes through a machine.
Your product now has two users. The human wants confidence, narrative, control, social proof, trust, and a reason to believe the product will make them look smart. The agent wants structured context, stable interfaces, low ambiguity, small tool surfaces, clear errors, cheap execution, and a path it can complete without rescue.
Great companies will serve both. Weak companies will serve the human beautifully and fail the machine silently.
The second objection is also true: parametric lock-in will weaken as agents get better at retrieval, browsing, benchmarking, sandboxing, and runtime evaluation. And as that happens, growth engineering evolves and becomes more measurable.
The moat shifts from static memory to continuous reselection. The winning product will not merely be the one the model remembers once. It will be the one agents can find, test, execute, trust, and choose again and again.
That is a better world for founders. You cannot buy your way into last year’s training run, but you can make your product work this year on the first try.
Distribution now has to be engineered
The old growth question was how to get more people into the funnel. The new one is how to become the path an agent takes before a person compares the options.
That work lives in docs, APIs, examples, schemas, registries, tool descriptions, templates, evaluation harnesses, pricing rails, payment flows, and the public code that teaches the next model what normal looks like.
It is growth because it decides adoption. It is engineering because the adoption surface is now built.
The growth engineer in this era measures model memory, runtime discoverability, harness placement, token-to-value, first execution, error recovery, reselection, and public signal. They understand that a product can lose distribution before it loses revenue, and that a startup can win the next model before the market sees it.
That is what The Growth Engineer is for: helping ambitious founders become the default in their category before the category hardens.
The founders I want to back
I come to investing as a product builder and growth engineer.
I want to back deeply technical AI founders, who move fast, have a history of building in public and care deeply about becoming the default in their category.
I learned that at W&B. One reason we won was that Lukas, our CEO, cared deeply about user growth, he called it the oxygen for the company. We looked at the growth metrics every week. We cared about them like our lives depended on them, because in the early years they did. The dogged pursuit of growth metrics allowed us to make hard decisions until W&B became part of the daily workflow for millions of AI engineers.
That is the kind of founders I want to work with now: someone who treats distribution as part of the product from the beginning, someone who won’t settle for anything but being the default in their category.
If you are a founder working on an ambitious AI startup, reach out. I’d love to be your first institutional check and help you become the default in your category. We invest $500k-$1M in pre-seed and seed rounds, with occasional Series A checks.
Send me a short note with what you are building, a demo and what has to be true for you to become the default.